








Our new cloud service for high-performance computing, together with HPC-specific APIs, hugely simplifies management of HPC environments composed of multi-cloud resource tiers. And you can continue to use your familiar, preferred HPC management tools!

In order to get complex analytics or simulation work done, high-performance computing (HPC) user communities nowadays can access a vast variety of computing resources. Beyond just one dedicated system, access is common to systems of disparate systems.
As an example, large supercomputing centers are tendering computational services to a number of user communities; it is common to also extend that service to public CSPs in case of elasticity requirements. Commercial enterprises are offering computational services with an ability to securely run jobs in a multi-site environment, or on a different dedicated HPC system or a shared computing resource.
When delivering hybrid cloud service environments for HPC, our objective has become to help to optimize investment to drive outcomes while considering the heterogeneity and availability of computing systems. There are many considerations around why to use a multi-tiered cloud platform integrated with an HPC environment around factors like: cost-value; security; data gravity (location, latency); fault-tolerance; license availability; usage patterns; access to several generations of hardware technology; blended financial and technology commitment models, from on-demand to reserve on a more granular basis; specific stage in product or tech lifecycle; usage of adjacent services, and more.
Modern converged HPC-AI solutions now may be offered via unified hardware infrastructure, providing customers with a cloud-anywhere subscription and consumption model and offering access to software, services, and support for complex computational, analytics, and data transaction workflows. The end result for a customer is a customized, multi-tiered, hybrid cloud platform that optimizes the usage of a diverse set of on-premises and off-premises resources (multi-site, a colocation managed shared compute capacity buffer, or a public cloud) while optimizing complex workflows to drive desired outcomes. Selection on “where to run my job” in this complex environment is regarded by all of our customers as a critical and difficult problem to solve.
HPE multi-cloud connector and its APIs
HPE multi-cloud connector and its APIs are key foundational elements of HPE GreenLake platform that allow the extension and orchestration of our HPC cloud services to be able to compute on multiple targets.
Some of the fruits of this ongoing innovation effort are available right now, in the form of our new multi-cloud connector and APIs, introduced in March. (See our announcement: HPE GreenLake edge-to-cloud platform delivers greater choice and simplicity.)1
Our multi-cloud connector is first of all a cloud service, a private HPC cloud, based on HPE GreenLake for HPC, with features such as managing users and their authentication methods; sharing access; resource metering and consumption monitoring; invoicing and billing; and setting business policies for subscription and consumption. Then, multi-cloud connector is a hybrid cloud service, with a control plane to manage access to multiple computing destinations, including on-premises infrastructure, colocations, supercomputers, and the cloud.
In addition, we offer a set of HPC-specific APIs for customers and partners to integrate with the multi-cloud connector. These APIs enable standardization of the HPC user experience while preserving customers’ existing ways like web portals, their own gateways and front-ends for interfacing with their computing platform and submitting a job in a multi-tiered cloud environment. Once standardized and compliant, the access to a service can be listed on our HPE GreenLake cloud services marketplace, augmenting a portfolio of services from our rich partner ecosystem. Such examples may include: CAE-as-a-service, crash-simulation-as-a-service, genomics-sequence-analytics-as-a-service, structural-biology-simulation-as-a-service, or blood-flow-simulation-as-a-service, etc.
Each of these services in the marketplace would optimally utilize a complex multi-cloud HPC environment and be accessible via HPE GreenLake cloud services marketplace. With this approach, built on HPE GreenLake for HPC cloud platform, our customers and partners would be able to offer and monetize their own cloud platforms for compute and data services among their user communities, ISVs, managed service providers, consortiums, and alliances.
This way, via the multi-cloud connector and its APIs, our customers and partners would integrate a wide spectrum of HPC user experiences and workflows while preserving what their user community is accustomed to use to submit an HPC job or an AI experiment, even including those who chose, for a common approach, to use Command Line Interface (CLI) by directly interfacing with a specific system.
There also might be user-specific ways to monitor a running computing job, view available resources, view what was consumed, and track the spend. Customers or partners can now build their value-added software and services across digital platform suites and workload interface portals – while leveraging their own tool sets across container management, cluster management, orchestration, data management, workflow creation and more.
You may ask, what about Data Management? This would be a topic for a blog on its own. HPE has a superb product, HPE Data Management Framework 7, which would be a key building block of data management services in our holistic multi-cloud HPC solution. Selection of source and destination of data for a computing job is part of the job submission process. Therefore, this can be addressed through job submission APIs derived from a job submission command if using CLI, or from an application’s data manipulation widgets (like file managers) that are part of workload interface portals. In addition, the presence of a dataset can be an attribute of a computing target (cluster), and therefore we could perform filtering operations and orchestration with resource-filtering APIs.
Underneath such workflow-aaS lies a multi-cloud connector that orchestrates the selection of the “right” computing target for a job, and does it either manually, by exposing the “knobs” to the user (like price/performance, data locality info, data transfer time/cost, applications license info, special hardware capabilities or security attributes, etc.), or automatically, given specified business policy on “where to run a job” for a specific user/group.
The figure below shows how the multi-cloud connector and APIs might fit into a unified HPC and AI-as-a-Service platform.
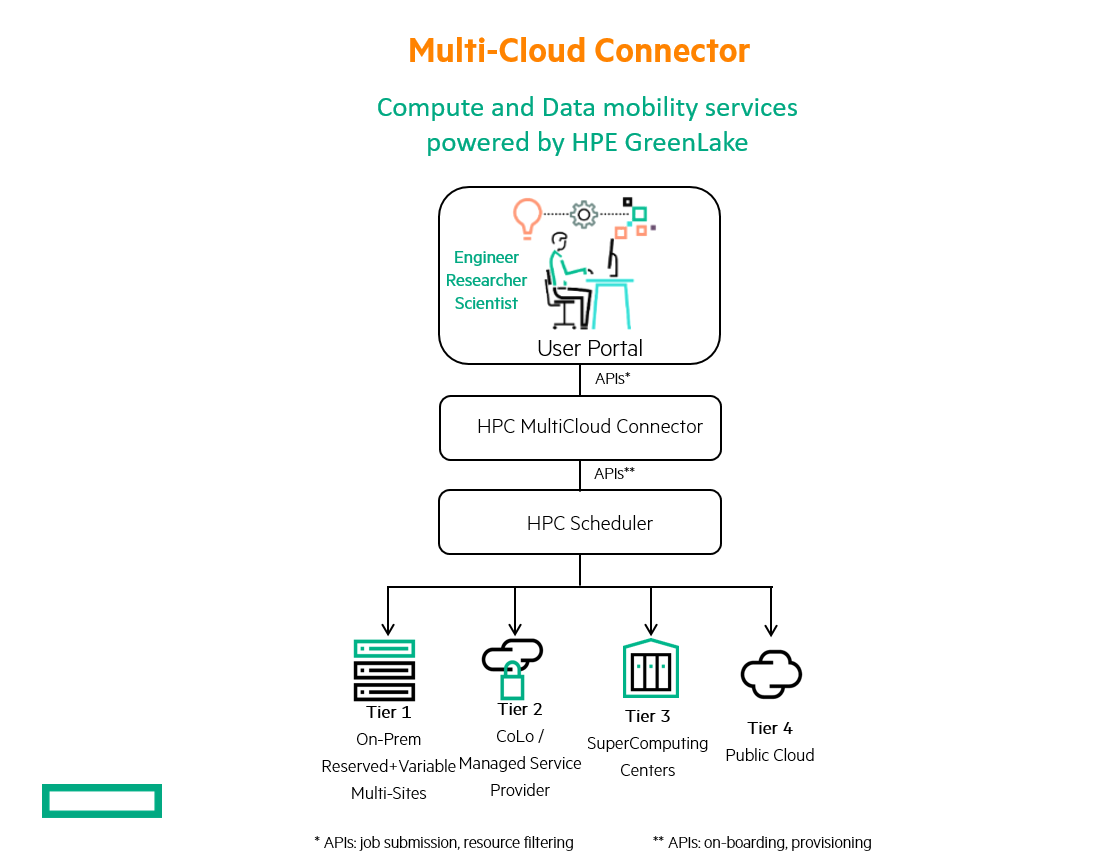
How it works: 5 types of APIs
There are five categories of APIs that extend customers’ and partners’ solutions from a single compute target to a multi-cloud environment (across private HPC cloud, collocated shared compute capacity, or a public cloud):
- User management/identity management APIs, including APIs to ensure single sign-on
- Job/experiment submission APIs, including APIs for job placement, configurations, data upload/download, notification handlers
- Resource-filtering APIs, including APIs to see available resources, setting matching policies, and access to resource consumption data
- Cluster/queue on-boarding APIs, including APIs to probe system capabilities
- Provisioning APIs.
As an example, let’s take a user who typically leverages a digital platform to work on engineering innovations or discoveries. When signing on to the platform, they also authenticate themselves with HPE GreenLake cloud services, and will initialize access to an appropriate set of resources via identity access management (IAM) APIs (1 in the list above).
Then, when they are ready to a submit a job, they do so with job submission APIs (2), so the job is routed to a suitable computing destination and configured and executed appropriately at that destination. Users could also impact resource selection by setting up resource-filtering APIs (3) on the number of cores and GPUs, memory size and interconnect for availability or optimal execution. They could also set up business rules defining optimal outcomes as a function of price/performance, energy consumption, data location, data latency, license availability and other factors which need to be considered for optimal job placement.
Meanwhile, through cluster on-boarding APIs (4), a cluster/queue that becomes available or comes off-line has to notify the entire service that a new resource may be available. If newly added compute resources need to be provisioned or verified on compatibility, the use of provisioning APIs (5) can refactor the system to add them to the fleet.
See the figure below for an example of an integrated workflow.
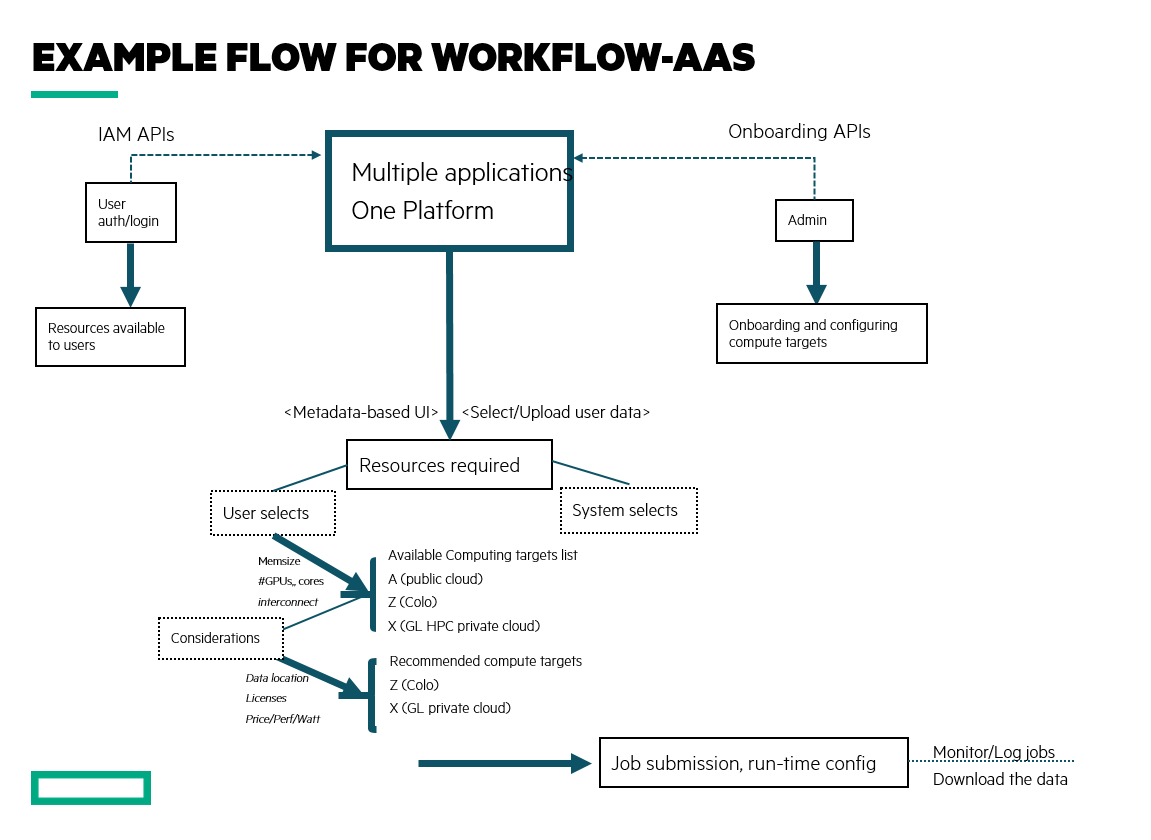
A new kind of hybrid cloud for HPC
As a result, each of the services in HPE GreenLake for HPC cloud platform marketplace, in its foundation, will be based on a unique ability of the HPE GreenLake private cloud platform to programmatically, through the APIs, orchestrate HPC job routing to selected computing destinations on a “best-fit” basis, as a real breakthrough in the evolution of HPC in hybrid cloud.
We’re seeing growing interest in the industry for such a solution, enabling commercial enterprises and research institutions to manage their diverse pool of computing resources according to their business policies. Our multi-cloud connector and HPC-specific APIs enable our customers to navigate a complex hybrid HPC cloud environment and select the right computing destination for their job while continuing to work in their own preferred environments.
Learn more about HPE GreenLake for High Performance Computing.
Related resource:
Max Alt blog: HPC just got (even) easier

Max Alt
Hewlett Packard Enterprise
twitter.com/HPE_AI
linkedin.com/showcase/hpe-servers-and-systems/
hpe.com/solutions
Max has a unique background with almost 30 years of experience in software performance technologies and high performance computing. He is both an entrepreneur and a large-scale enterprise leader. He founded several tech start-ups in the Bay area and he spent 18 years at Intel in various engineering and leadership roles including developing next generation super-computing technologies. Max’s strongest areas of expertise lie in computer and server architectures, cloud technologies, operating systems, compilers, and software engineering. Prior to joining HPE, Max was SVP AI & HPC Technology at Core Scientific that acquired Atrio in 2020 where Max was the CEO & Founder.



