







The next BriefingsDirect podcast explores how artificial intelligence (AI) increasingly supports IT operations.
One of the most successful uses of machine learning (ML) and AI for IT efficiency has been the InfoSight technology developed at Nimble Storage, now part of Hewlett Packard Enterprise (HPE).
Initially targeting storage optimization, HPE InfoSight has emerged as a broad and inclusive capability for AIOps across an expanding array of HPE products and services.
Please welcome a Nimble Storage founder, along with a cutting-edge machine learning architect, to examine the expanding role and impact of HPE InfoSight in making IT resiliency better than ever.
Listen to the podcast. Find it on iTunes. Read a full transcript or download a copy.
To learn more about the latest IT operations solutions that help companies deliver agility and edge-to-cloud business continuity, we’re joined by Varun Mehta, Vice President and General Manager for InfoSight at HPE and founder of Nimble Storage, and David Adamson, Machine Learning Architect at HPE InfoSight. The discussion is moderated by Dana Gardner, Principal Analyst at Interarbor Solutions.
Here are some excerpts:
Gardner: Varun, what was the primary motivation for creating HPE InfoSight? What did you have in mind when you built this technology?
Mehta: Various forms of call home were already in place when we started Nimble, and that’s what we had set up to do. But then we realized that the call home data was used to do very simple actions. It was basically to look at the data one time and try and find problems that the machine was having right then. These were very obvious issues, like a crash. If you had had any kind of software crash, that’s what call home data would identify.

We found that if instead of just scanning the data one time, if we could store it in a database and actually look for problems over time in areas wider than just a single use, we could come up with something very interesting. Part of the problem until then was that a database that could store this amount of data cheaply was just not available, which is why people would just do the one-time scan.
The enabler was that a new database became available. We found that rather than just scan once, we could put everyone’s data into one place, look at it, and discover issues across the entire population. That was very powerful. And then we could do other interesting things using data science such as workload planning from all of that data. So the realization was that if the databases became available, we could do a lot more with that data.
Gardner: And by taking advantage of that large data capability and the distribution of analytics through a cloud model, did the scope and relevancy of what HPE InfoSight did exceed your expectations? How far has this now come?
Mehta: It turned out that this model was really successful. They say that, “imitation is the sincerest form of flattery.” And that was proven true, too. Our customers loved it, our competitors found out that our customers loved it, and it basically spawned an entire set of features across all of our competitors.
The reason our customers loved it — followed by our competitors — was that it gave people a much broader idea of the issues they were facing. We then found that people wanted to expand this envelope of understanding that we had created beyond just storage.
Data delivers more than a quick fix
And that led to people wanting to understand how their hypervisor was doing, for example. And so, we expanded the capability to look into that. People loved the solution and wanted us to expand the scope into far more than just storage optimization.
Gardner: David, you hear Varun describing what this was originally intended for. As a machine learning architect, how has HPE InfoSight provided you with a foundation to do increasingly more when it comes to AIOps, dependability, and reliability of platforms and systems?
The database is full of data that not only tracks everything longitudinally across the installed base, but also over time. The richness of that data gives us features we otherwise could not have conceived of. Many issues can now be automated away.
Adamson: As Varun was describing, the database is full of data that not only tracks everything longitudinally across the installed base, but also over time. The richness of that data set gives us an opportunity to come up with features that we otherwise wouldn’t have conceived of if we hadn’t been looking through the data. Also very powerful from InfoSight’s early days was the proactive nature of the IT support because so many simple issues had now been automated away.
That allowed us to spend time investigating more interesting and advanced problems, which demanded ML solutions. Once you’ve cleaned up the Pareto curve of all the simple tasks that can be automated with simple rules or SQL statements, you uncover problems that take longer to solve and require a look at time series and telemetry that’s quantitative in nature and multidimensional. That data opens up the requirement to use more sophisticated techniques in order to make actionable recommendations.
Gardner: Speaking of actionable, something that really impressed me when I first learned about HPE InfoSight, Varun, was how quickly you can take the analytics and apply them. Why has that rapid capability to dynamically impact what’s going on from the data proved so successful?
Support to succeed
Mehta: It turned out to be one of the key points of our success. I really have to compliment the deep partnership that our support organization has had with the HPE InfoSight team.
The support team right from the beginning prided themselves on providing outstanding service. Part of the proof of that was incredible Net Promoter scores (NPS), which is this independent measurement of how satisfied customers are with our products. Nimble’s NPS score was 86, which is even higher than Apple. We prided ourselves on providing a really strong support experience to the customer.
Whenever a problem would surface, we would work with the support team. Our goal was for a customer to see a problem only once. And then we would rapidly fix that problem for every other customer. In fact, we would fix it preemptively so customers would never have to see it. So, we evolved this culture of identifying problems, creating signatures for these problems, and then running everybody’s data through the signatures so that customers would be preemptively inoculated from these problems. That’s why it became very successful.
Gardner: It hasn’t been that long since we were dealing with red light-green light types of IT support scenarios, but we’ve come a long way. We’re not all the way to fully automated, lights-out, machines running machines operations.
David, where do you think we are on that automated support spectrum? How has HPE InfoSight helped change the nature of systems’ dependability, getting closer to that point where they are more automated and more intelligent?
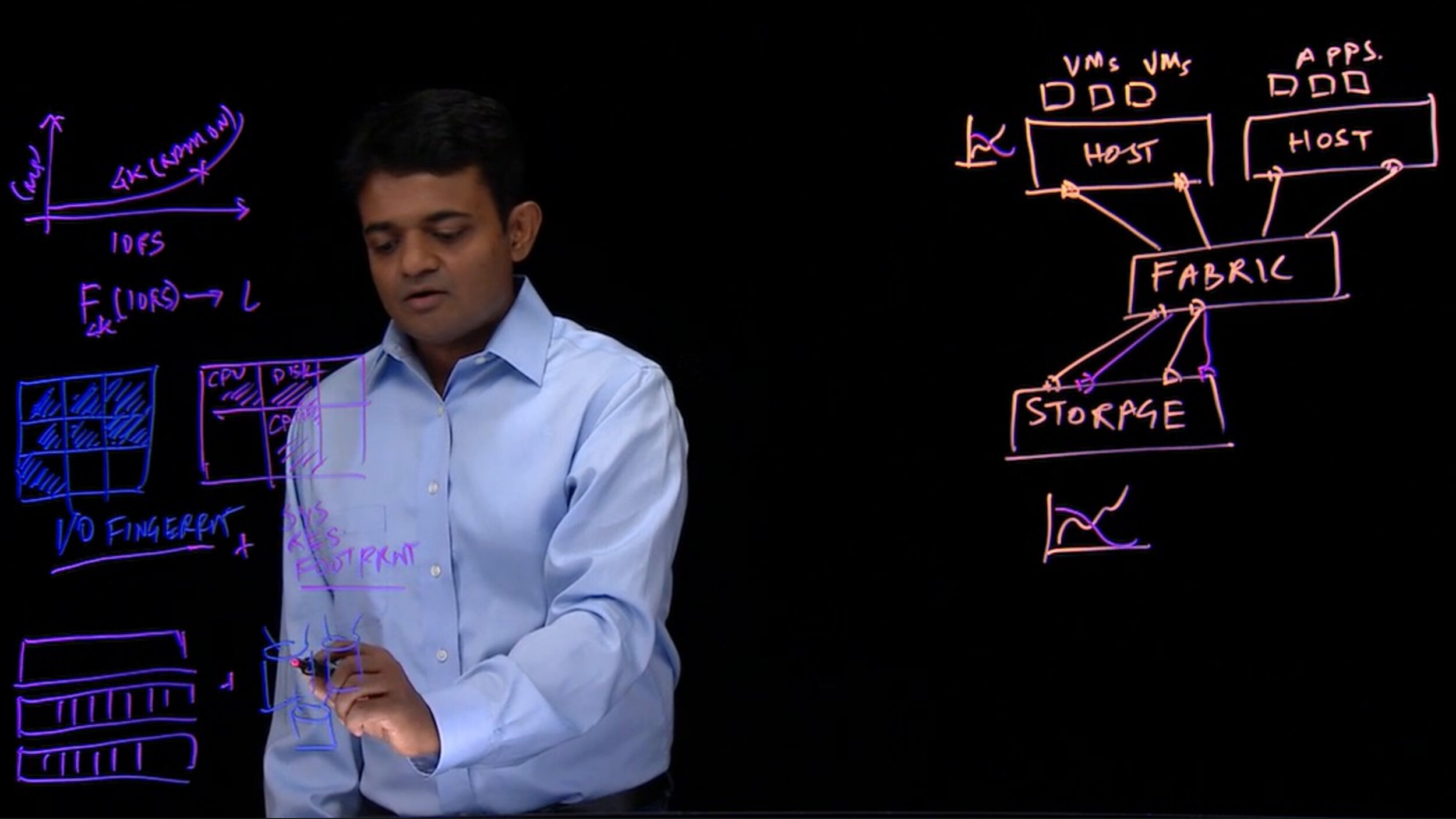
Adamson: The challenge with fully automated infrastructure stems from the variety of different components in the environments — and all of the interoperability among those components. If you look at just a simple IT stack, they are typically applications on top of virtual machines (VMs), on top of hosts — they may or may not have independent storage attached – and then the networking of all these components. That’s discounting all the different applications and various software components required to run them.
There are just so many opportunities for things to break down. In that context, you need a holistic perspective to begin to realize a world in which the management of that entire unit is managed in a comprehensive way. And so we strive for observability models and services that collect all the data from all of those sources. If we can get that data in one place to look at the interoperability issues, we can follow the dependency chains.

But then you need to add intelligence on top of that, and that intelligence needs to not only understand all of the components and their dependencies, but also what kinds of exceptions can arise and what is important to the end users.
So far, with HPE InfoSight, we go so far as to pull in all of our subject matter expertise into the models and exception-handling automation. We may not necessarily have upfront information about what the most important parts of your environment are. Instead, we can stop and let the user provide some judgment. It’s truly about messaging to the user the different alternative approaches that they can take. As we see exceptions happening, we can provide those recommendations in a clean and interpretable way, so [the end user] can bring context to bear that we don’t necessarily have ourselves.
Gardner: And the timing for these advanced IT operations services is very auspicious. Just as we’re now able to extend intelligence, we’re also at the point where we have end-to-end requirements – from the edge, to the cloud, and back to the data center.
And under such a hybrid IT approach, we are also facing a great need for general digital transformation in businesses, especially as they seek to be agile and best react to the COVID-19 pandemic. Are we able yet to apply HPE InfoSight across such a horizontal architecture problem? How far can it go?
Seeing the future: End-to-end visibility
Mehta: Just to continue from where David started, part of our limitation so far has been from where we began. We started out in storage, and then as Nimble became part of HPE, we expanded it to compute resources. We targeted hypervisors; we are expanding it now to applications. To really fix problems, you need to have end-to-end visibility. And so that is our goal, to analyze, identify, and fix problems end-to-end.
That is one of the axis of development we’re pursuing. The other axis of development is that things are just becoming more-and-more complex. As businesses require their IT infrastructure to become highly adaptable they also need scalability, self-healing, and enhanced performance. To achieve this, there is greater-and-greater complexity. And part of that complexity has been driven by really poor utilization of resources.
Go back 20 years and we had standalone compute and storage machines that were not individually very well-utilized. Then you had virtualization come along, and virtualization gave you much higher utilization — but it added a whole layer of complexity. You had one machine, but now you could have 10 VMs in that one place.
Now, we have containers coming out, and that’s going to further increase complexity by a factor of 10. And right on the horizon, we have serverless computing, which will increase the complexity another order of magnitude.
Complexity is increasing, interconnectedness is increasing, and yet the demands on the business to stay agile, competitive, and scalable are also increasing. It’s really hard for IT administrators to stay on top of this. That’s why you need end-to-end automation.
So, the complexity is increasing, the interconnectedness is increasing, and yet the demands on businesses to stay agile and competitive and scalable are also increasing. It’s really hard for IT administrators to stay on top of this. And that’s why you need end-to-end automation and to collect all of the data to actually figure out what is going on. We have a lot of work cut out for us.
There is another area of research, and David spends a lot of time working on this, which is you really want to avoid false positives. That is a big problem with lots of tools. They provide so many false positives that people just turn them off. Instead, we need to work through all of your data to actually say, “Hey, this is a recommendation that you really should pay attention to.” That requires a lot of technology, a lot of ML, and a lot of data science experience to separate the wheat from the chaff.
One of the things that’s happened with the COVID-19 pandemic response is the need for very quick response stats. For example, people have had to quickly set up web sites for contact tracing, reporting on the diseases, and for vaccines use. That shows an accelerated manner in how people need digital solutions — and it’s just not possible without serious automation.
Gardner: Varun just laid out the complexity and the demands for both the business and the technology. It sounds like a problem that mere mortals cannot solve. So how are we helping those mere mortals to bring AI to bear in a way that allows them to benefit – but, as Varun also pointed out, allows them to trust that technology and use it to its full potential?
Complexity requires automated assistance
Adamson: The point Varun is making is key. If you are talking about complexity, we’re well beyond the point where people could realistically expect to log-in to each machine to find, analyze, or manage exceptions that happen across this ever-growing, complex regime.
Even if you’re at a place where you have the observability solved, and you’re monitoring all of these moving parts together in one place — even then, it easily becomes overwhelming, with pages and pages of dashboards. You couldn’t employ enough people to monitor and act to spot everything that you need to be spotting.
You need to be able to trust automated exception [finding] methods to handle the scope and complexity of what people are dealing with now. So that means doing a few things.
People will often start with naïve thresholds. They create manual thresholds to give alerts to handle really critical issues, such as all the servers went down.
But there are often more subtle issues that show up that you wouldn’t necessarily have anticipated setting a threshold for. Or maybe your threshold isn’t right. It depends on context. Maybe the metrics that you’re looking at are just the raw metrics you’re pulling out of the system and aren’t even the metrics that give a reliable signal.
What we see from the data science side is that a lot of these problems are multi-dimensional. There isn’t just one metric that you could set a threshold on to get a good, reliable alert. So how do you do that right?
For the problems that IT support provides to us, we apply automation and we move down the Pareto chart to solve things in priority of importance. We also turn to ML models. In some of these cases, we can train a model from the installed base and use a peer-learning approach, where we understand the correlations between problem states and indicator variables well enough so that we can identify a root cause for different customers and different issues.
Sometimes though, if the issue is rare enough, scanning the installed base isn’t going to give us a high enough signal to the noise. Then we can take some of these curated examples from support and do a semi-supervised loop. We basically say, “We have three examples that are known. We’re going to train a model on them.” Maybe it’s a few tens of thousands of data points, but it’s still in the three examples, so there’s co-correlation that we are worried about.
In that case we say: “Let me go fishing in that installed base with these examples and pull back what else gets flagged.” Then we can turn those back over to our support subject matter experts and say, “Which of these really look right?” And in that way, you can move past the fact that your starting data set of examples is very small and you can use semi-supervised training to develop a more robust model to identify the issues.
Gardner: As you are refining and improving these models, one of the benefits in being a part of HPE is to access growing data sets across entire industries, regions, and in fact the globe. So, Varun, what is the advantage of being part of HPE and extending those datasets to allow for the budding models to become even more accurate and powerful over time?
Gain a global point of view
Mehta: Being part of HPE has enabled us to leapfrog our competition. As I said, our roots are in storage, but really storage is just the foundation of where things are located in an organization. There is compute, networking, hypervisors, operating systems, and applications. With HPE, we certainly now cover the base infrastructure, which is storage followed by compute. At some point we will bring in networking. We already have hypervisor monitoring, and we are actively working on application monitoring.
HPE has allowed us to radically increase the scope of what we can look at, which also means we can radically improve the quality of the solutions we offer to our customers. And so it’s been a win-win solution, both for HPE where we can offer a lot of different insights into our products, and for our customers where we can offer them faster solutions to more kinds of problems.
Gardner: David, anything more to offer on the depth, breadth, and scope of data as it’s helping you improve the models?
Adamson: I certainly agree with everything that Varun said. The one thing I might add is in the feedback we’ve received over time. And that is, one of the key things in making the notifications possible is getting us as close as possible to the customer experience of the applications and services running on the infrastructure.
Gaining additional measurements from the applications themselves is going to give us the ability to differentiate ourselves, to find the important exceptions to the end user, what they really want us to take action on, the events that are truly business-critical.
We’ve done a lot of work to make sure we identify what look like meaningful problems. But we’re fundamentally limited if the scope of what we measure is only at the storage or hypervisor layer. So gaining additional measurements from the applications themselves is going to give us the ability to differentiate ourselves, to find the important exceptions to the end user, what they really want to take action on. That’s critical for us — not sending people alerts they are not interested in but making sure we find the events that are truly business-critical.
Gardner: And as we think about the extensibility of the solution — extending past storage into compute, ultimately networking, and applications — there is the need to deal with the heterogeneity of architecture. So multicloud, hybrid cloud, edge-to-cloud, and many edges to cloud. Has HPE InfoSight been designed in a way to extend it across different IT topologies?
Across all architecture
Mehta: At heart, we are building a big data warehouse. You know, part of the challenge is that we’ve had this explosion in the amount of data that we can bring home. For the last 10 years, since InfoSight was first developed, the tools have gotten a lot more powerful. What we now want to do is take advantage of those tools so we can bring in more data and provide even better analytics.
The first step is to deal with all of these use cases. Beyond that, there will probably be custom solutions. For example, you talked about edge-to-cloud. There will be locations where you have good bandwidth, such as a colocation center, and you can send back large amounts of data. But if you’re sitting as the only compute in a large retail store like a Home Depot, for example, or a McDonald’s, then the bandwidth back is going to be limited. You have to live within that and still provide effective monitoring. So I’m sure we will have to make some adjustments as we widen our scope, but the key is having a really strong foundation and that’s what we’re working on right now.
Gardner: David, anything more to offer on the extensibility across different types of architecture, of analyzing the different sources of analytics?
Adamson: Yes, originally, when we were storage-focused and grew to the hypervisor level, we discovered some things about the way we keep our data organized. If we made it more modular, we could make it easier to write simple rules and build complex models to keep turnaround time fast. We developed some experience and so we’ve taken that and applied it in the most recent release of recommendations into our customer portal.
We’ve modularized our data model even further to help us support more use cases from environments that may or may not have specific components. Historically, we’ve relied on having Nimble Storage, they’re a hub for everything to be collected. But we can’t rely on that anymore. We want to be able to monitor environments that don’t necessarily have that particular storage device, and we may have to support various combinations of HPE products and other non-HPE applications.

Modularizing our data model to truly accommodate that has been something that we started along the path for and I think we’re making good strides toward.
The other piece is in terms of the data science. We’re trying to leverage longitudinal data as much as possible, but we want to make sure we have a sufficient set of meaningful ML offerings. So we’re looking at unsupervised learning capabilities that we can apply to environments for which we don’t have a critical mass of data yet, especially as we onboard monitoring for new applications. That’s been quite exciting to work on.
Gardner: We’ve been talking a lot about the HPE InfoSight technology, but there also has to be considerations for culture. A big part of digital transformation is getting silos between people broken down.
Is there a cultural silo between the data scientists and the IT operations people? Are we able to get the IT operations people to better understand what data science can do for them and their jobs? And perhaps, also allow the data scientists to understand the requirements of a modern, complex IT operations organization? How is it going between these two groups, and how well are they melding?
IT support and data science team up
Adamson: One of the things that Nimble did well from the get-go was have tight coupling between the IT support engineers and the data science team. The support engineers were fielding the calls from the IT operations guys. They had their fingers on the pulse of what was most important. That meant not only building features that would help our support engineers solve their escalations more quickly, but also things that we can productize for our customers to get value from directly.
Gardner: One of the great ways for people to better understand a solution approach like HPE InfoSight is through examples. Do we have any instances that help people understand what it can do, but also the paybacks? Do we have metrics of success when it comes to employing HPE InfoSight in a complex IT operations environment?
Mehta: One of the examples I like to refer to was fairly early in our history but had a big impact. It was at the University Hospital of Basel in Switzerland. They had installed a new version of VMware, and a few weeks afterward things started going horribly wrong with their implementation that included a Nimble Storage device. They called VMware and VMware couldn’t figure it out. Eventually they called our support team and using InfoSight, our support team was able to figure it out really quickly. The problem turned out to be a result of a new version of VMware. If there was a hold up in the networking, some sort of bottleneck in their networking infrastructure, this VMware version would try really hard to get the data through.
So instead of submitting each write once to the storage array once, it would try 64 times. Suddenly, their traffic went up by 64 times. There was a lot of pounding on the network, pounding on the storage system, and we were able to tell with our analytics that, “Hey this traffic is going up by a huge amount.” As we tracked it back, it pointed to the new version of VMware that had been loaded. We then connected with the VMware support team and worked very closely with all of our partners to identify this bug, which VMware very promptly fixed. But, as you know, it takes time for these fixes to roll out to the field.
We were able to preemptively alert other people who had the same combination of VMware on Nimble Storage and say, “Guys, you should either upgrade to this new patch that VMware has made or just be aware that you are susceptible to this problem.”
So that’s a great example of how our analytics was able to find a problem, get it fixed very quickly — quicker than any other means possible — and then prevent others from seeing the same problem.
Gardner: David, what are some of your favorite examples of demonstrating the power and versatility of HPE InfoSight?
Adamson: One that comes to mind was the first time we turned to an exception-based model that we had to train. We had been building infrastructure designed to learn across our installed base to find common resource bottlenecks and identify and rank those very well. We had that in place, but we came across a problem that support was trying to write a signature for. It was basically a drive bandwidth issue.
But we were having trouble writing a signature that would identify the issue reliably. We had to turn to an ML approach because it was fundamentally a multidimensional problem. If we looked across, we have had probably 10 to 20 different metrics that we tracked per drive per minute on each system. We needed to, from those metrics, come up with a good understanding of the probability that this was the biggest bottleneck on the system. This was not a problem we could solve by just setting a threshold.

So we had to really go in and say, “We’re going to label known examples of these situations. We’re going to build the sort of tooling to allow us to do that, and we’re going to put ourselves in a regime where we can train on these examples and initiate that semi-supervised loop.”
We actually had two to three customers that hit that specific issue. By the time we wanted to put that in place, we were able to find a few more just through modeling. But that set us up to start identifying other exceptions in the same way.
We’ve been able to redeploy that pattern now several times to several different problems and solve those issues in an automated way, so we don’t have to keep diagnosing the same known flavors of problems repeatedly in the future.
Gardner: What comes next? How will AI impact IT operations over time? Varun, why are you optimistic about the future?
Software eats the world
Mehta: I think having a machine in the loop is going to be required. As I pointed out earlier, complexity is increasing by leaps and bounds. We are going from virtualization to containers to serverless. The number of applications keeps increasing and demand on every industry keeps increasing.
Andreessen Horowitz, a famous venture capital firm once said, “Software is eating the world,” and really, it is true. Everything is becoming tied to a piece of software. The complexity of that is just huge. The only way to manage this and make sure everything keeps working is to use machines.
That’s where the challenge and opportunity is. Because there is so much to keep track of, one of the fundamental challenges is to make sure you don’t have too many false positives. You want to make sure you alert only when there is a need to alert. It is an ongoing area of research.
There’s a big future in terms of the need for our solutions. There’s plenty of work to keep us busy to make sure we provide the appropriate solutions. So I’m really looking forward to it.

There’s also another axis to this. So far, people have stayed in the monitoring and analytics loop and it’s like self-driving cars. We’re not yet ready for machines to take over control of our cars. We get plenty of analytics from the machines. We have backup cameras. We have radars in front that alert us if the car in front is braking too quickly, but the cars aren’t yet driving themselves.
It’s all about analytics yet we haven’t graduated from analytics to control. I think that too is something that you can expect to see in the future of AIOps once the analytics get really good, and once the false positives go away. You will see things moving from analytics to control. So lots of really cool stuff ahead of us in this space.
Gardner: David, where do you see HPE InfoSight becoming more of a game changer and even transforming the end-to-end customer experience where people will see a dramatic improvement in how they interact with businesses?
Adamson: Our guiding light in terms of exception handling is making sure that not only are we providing ML models that have good precision and recall, but we’re making recommendations and statements in a timely manner that come only when they’re needed — regardless of the complexity.
A lot of hard work is being put into making sure we make those recommendation statements as actionable and standalone as possible. We’re building a differentiator through the fact that we maintain a focus on delivering a clean narrative, a very clear-cut, “human readable text” set of recommendations.
And that has the potential to save a lot of people a lot of time in terms of hunting, pecking, and worrying about what’s unseen and going on in their environments.
Gardner: Varun, how should enterprise IT organizations prepare now for what’s coming with AIOps and automation? What might they do to be in a better position to leverage and exploit these technologies even as they evolve?
Pick up new tools
Mehta: My advice to organizations is to buy into this. Automation is coming. Too often we see people stuck in the old ways of doing things. They could potentially save themselves a lot of time and effort by moving to more modern tools. I recommend that IT organizations make use of the new tools that are available.
HPE InfoSight is generally available for free when you buy an HPE product, sometimes with only the support contract. So make use of the resources. Look at the literature with HPE InfoSight. It is one of those tools that can be fire-and-forget, which is you turn it on and then you don’t have to worry about it anymore.
It’s the best kind of tool because we will come back to you and tell you if there’s anything you need to be aware of. So that would be the primary advice I would have, which is to get familiar with these automation tools and analytics tools and start using them.
Gardner: I’m afraid we’ll have to leave it there. We have been exploring how HPE InfoSight has emerged as a broad and inclusive capability for AIOps across an expanding array of edge-to-cloud solutions. And we’ve learned how these expanding AIOps capabilities are helping companies deliver increased agility — and even accelerated digital transformation.
So please join me in thanking our guests, Varun Mehta, Vice President and General Manager for InfoSight at HPE and a founder of Nimble Storage. Thanks so much, Varun.
Mehta: Thank you, Dana.
Gardner: And we’ve also been here with David Adamson, Machine Learning Architect at HPE. Thanks so much, David.
Adamson: Thank you. It’s been a pleasure.
Gardner: And a big thank you as well to our audience for joining this sponsored BriefingsDirect AIOps innovation discussion. I’m Dana Gardner, Principal Analyst at Interarbor Solutions, your host for this ongoing series of Hewlett Packard Enterprise-supported discussions.
Thanks again for listening. Please pass this along to your IT community, and do come back next time.
Listen to the podcast. Find it on iTunes. Download the transcript. Sponsor: Hewlett Packard Enterprise.
A discussion on how HPE InfoSight has emerged as a broad and inclusive capability for AIOps across an expanding array of HPE products and services. Copyright Interarbor Solutions, LLC, 2005-2020. All rights reserved.
You may also be interested in:
· Nimble Storage leverages big data and cloud to produce data performance optimization on the fly
· How Digital Transformation Navigates Disruption to Chart a Better Course to the New Normal
· How REI used automation to cloudify infrastructure and rapidly adjust its digital pandemic response
· How the right data and AI deliver insights and reassurance on the path to a new normal
· How IT modern operational services enables self-managing, self-healing, and self-optimizing
· How HPE Pointnext Services ushers businesses to the new normal via an inclusive nine-step plan
· As containers go mainstream, IT culture should pivot to end-to-end DevSecOps
· AI-first approach to infrastructure design extends analytics to more high-value use cases
· How Intility uses HPE Primera intelligent storage to move to 100 percent data uptime
· As hybrid IT complexity ramps up, operators look to data-driven automation tools





