







How fine-grained data placement helps optimize application performance
Ellen Friedman
October 22, 2021
Does data locality matter? In an ideal world, after all the work you put into developing an analytics or AI application, you would have unlimited access to resources to run the application to get top performance when it’s deployed in production. But the world is not perfect.
Access may be hampered through latency caused by distance, limitations on compute power, transmission mediums, or poorly optimized databases. What can you do about these issues and how does fine-grained control of data locality help?
Getting the resources your applications need
Even though there are limitations on the availability of resources in any shared system, you don’t need resources at the same level at all points in the lifecycle of your data. For instance, with AI and machine learning projects, data latency and computational requirements change at various stages in the lifetime of models. The learning process, when models are trained, tends to be compute-intensive as compared to requirements when models run in production. Model training also requires high throughput, low-latency data access. It might seem ideal (if there were no limitations on resources) to run your entire machine learning project on high-performance computing (HPC) machines with specialized numerical accelerators such as graphical processing units (GPUs).
But while these are ideal for the model training phase, they may be less useful for the high-bulk, low-compute steps of raw data ingestion, data exploration, and initial processing for feature extraction. Instead, you may get the best net performance by carrying out these operations with data on traditional spinning media, especially if you live on a fixed budget (like everyone I know).
The point is that it’s not just real-world limitations on resources that drive the need to place data on different types of storage media. For top performance, you’d want to consider how the application processes the data. For certain, you’d want flexibility in any event.
You should be able to get the resources your applications need — when you need them and where you need them.
To make this work, the system on which your applications are deployed must allocate resources efficiently. The good news is that with a data infrastructure engineered to support scale-efficiency through granular data placement, it’s easy to optimize resource use and, in turn, to maximize application performance. Here’s how.
Match storage type to data requirements to maximize performance
The key to optimizing application performance and resource usage is to be able to match data throughput, latency and total size requirements with the appropriate type of storage media. Keep in mind that to get the full benefit of high-performance storage, it’s important to support GPUs and other accelerators from a data point of view.
In large systems, this optimization is accomplished by giving dedicated HPC machines high-performance storage, such as solid-state disks (SSDs) or nVME drives, and provisioning regular machines with slower, spinning media (HDDs), capable of handling large amounts of data storage at a lower cost. This type of large-scale cluster is depicted in Figure 1.

Figure 1. Large cluster containing a combination of dedicated, fast-compute/fast storage nodes (orange) and regular nodes/slower storage devices (green)
In the figure above, the orange squares represent SSDs, and orange lines represent machines with computational accelerators (such as GPUs). Green cylinders stand for slower spinning storage media (HDDs) and servers with green lines indicate traditional CPUs. In a typical machine learning/AI scenario, raw data is ingested on the non-HPC machines, where data exploration and feature extraction would take place on very large amounts of raw data. In a scale-efficient system, bulk analytic workloads, such as monthly billing, would also take place on the non-HPC (green) machines.
Once feature extraction is complete, training data is written to fast storage machines (orange) with SSDs and GPUs, ready to support the model training process. Other compute-intensive applications, such as simulations, would also run on the fast machines.
Smaller systems (clusters with less than 20 machines) often cannot afford dedicated HPC machines with high-performance storage. Instead, the need for high-performance computing is met by employing some heterogeneous mix — nodes with fast-compute capabilities but with a mix of different kinds of data storage devices rather than just SSDs. This arrangement is shown in Figure 2.
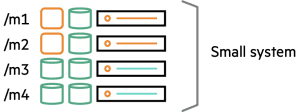
Figure 2. Small cluster containing fast-compute nodes (orange) having a mixture of SSDs (orange squares) plus slower HDDs (green cylinders) and regular nodes with HDDs only.
Similar to the earlier example, you need a way to assign what data will be placed on which machines. Fortunately, HPE Ezmeral Data Fabric lets you use storage labels to do just that.
Fine-grained data locality with HPE Ezmeral Data Fabric
HPE Ezmeral Data Fabric is a highly scalable, unifying data infrastructure engineered for data storage, management, and motion. Data fabric is software-defined and hardware agnostic. It lets you conveniently position data at the level of different racks, machines, or even different storage types within machines.
Figure 3 below shows how easy it is to create a data fabric volume, assign topology and apply data placement policies via storage labels. (A data fabric volume is a data management unit holding files, directories, NoSQL tables, and event streams all together that act like directories with superpowers for data management. Many policies, including data placement, are assigned to volumes.)
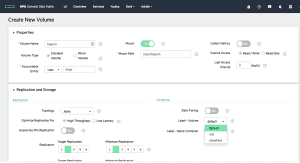
Figure 3. Screenshot of the control plane for HPE Ezmeral Data Fabric.
What happens if you need cross-cutting requirements for data placement? Data fabric lets you define data locality to address multiple goals, such as placement across multiple racks within topologies designated for different failure domains plus additional requirements for particular storage media imposed by assigning storage labels. Locality of the data fabric volume would have to meet both requirements.
Figure 4 illustrates an example of fine-grained data placement accomplished using storage labels in a cluster with heterogeneous machines.
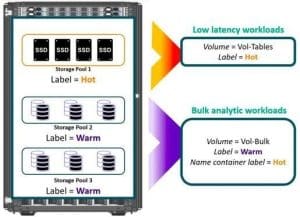
Figure 4. Using the storage labels feature of HPE Ezmeral Data Fabric for differential data placement on particular types of storage devices at the sub-machine level.
Benefits of high-performance metadata with HPE Ezmeral Data Fabric
Performance in distributed systems running many different applications is further enhanced by fine-grained data placement using HPE Ezmeral Data Fabric storage labels. This capability lets you easily assign data locality down to the level of storage pools, a unit of storage within a machine made up of multiple disks. To understand how this additional performance boost works, you’ll need a little background information about the data fabric and to understand how metadata is handled.
HPE Ezmeral Data Fabric uses a large unit of data storage, known as a data fabric container (not to be confused with a Kubernetes container, despite the similarity in the name) as the unit of replication. Data replication is an automatic feature of the data fabric – the basis for data fabric’s self-healing capabilities – with data replicas spread across multiple machines by default. But you can also specify particular data placement policies, and data fabric containers and their replicas will automatically be placed according to the policies you apply.
Data fabric also has a special container, known as a name container, which holds metadata for the files, directories, tables, and event streams associated with a data fabric volume. The name container is a strength of the HPE Ezmeral Data Fabric design because it provides a way for metadata to be distributed across a cluster, resulting in extreme reliability and high performance.
With the fine granularity for data placement afforded by the storage labels feature, data fabric containers and their replicas can have one placement policy while the name container can have a different policy. As Figure 4 shows, you can apply a label “Warm” to position data for bulk workloads on storage pools with slower devices while maintaining the metadata for that volume on fast solid-state devices by applying the label “Hot” to the name container.
This situation can result in significant throughput improvements in processes such as massive disk-based sorts where a very large number of spill files must be created quickly (requiring super-fast meta-data updates on SSDs) and then these spill files must be written very quickly (requiring fast sequential I/O that hordes of hard drives can provide). The combination can work better than either option in isolation by providing the right resources for the right micro-workloads.
Making the most of fine-grained data placement
Turns out you don’t need unlimited resources to get excellent performance for your applications when you take advantage of the fine granularity of data placement afforded by HPE Ezmeral Data Fabric. You can easily assign data topologies when you create a data volume, and you can use convenient storage labels for differential data placement on particular types of storage devices even down to different storage pools within machines. And with the added capability of placing metadata independently of data containers, you can further optimize performance for both bulk applications and in situations using many small files.
To find out more about the capabilities provided by HPE Ezmeral Data Fabric visit the data fabric platform page in the HPE Developer Community.
For a hands-on workshop highlighting data fabric volumes, go to HPE Ezmeral Data Fabric 101 – Get to know the basics around the data fabric.
To learn about data access management using HPE Ezmeral Data Fabric, read the New Stack article Data Access Control via ACEs vs ACLs: The power of “AND” and “NOT”.





